近期,华为诺亚方舟实验室、伦敦大学学院(UCL)、牛津大学等机构的研究人员联合提出了盘古智能体框架(Pangu-Agent),旨在解决人工智能智能体在面临挑战时的困境。这个革新性框架的主要特点是引入了结构化推理,从而帮助 AI 智能体克服了在多任务环境中学习和适应的挑战。
AI 强化学习的挑战
自人工智能诞生以来,开发能够解决复杂任务的多任务智能体一直是一个重要目标。强化学习方法被广泛应用于培养智能体的决策技能,但传统的强化学习方法在复杂环境中存在一定限制,尤其是通用智能体在多个随机环境中的学习与适应。
传统的强化学习方法通常使用单一的映射函数来定义策略,但在面对复杂环境时,这种方法可能表现不佳,因为无法满足通用智能体跨环境交互、适应和学习的要求。
盘古智能体框架的创新
盘古智能体框架的创新之处在于两个关键方面:一是将智能体的内部思维过程形式化为结构化推理的形式,二是展示了通过监督学习和强化学习来微调智能体的方法。
传统的强化学习主要关注通过感知输出行动的策略。但是,作者认为标准的强化学习管道中缺乏固有推理结构可能成为一个重大瓶颈。在这种情况下,梯度无法为所有深度网络提供足够的监督,因此引入结构化推理有助于强化学习克服这些挑战。
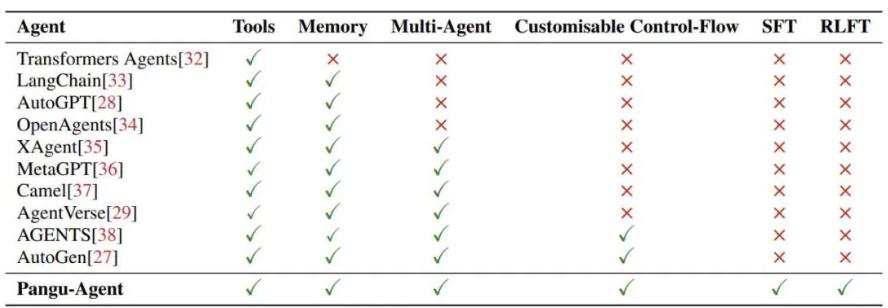
盘古智能体的功能与优势
盘古智能体框架的重要功能和优势包括:
- 结构化推理的重要性证明:盘古智能体展示了结构化推理如何有助于智能体的泛化能力,利用大型语言模型提供先验知识,实现跨领域的泛化。
- 多领域评估:作者在七个大型语言模型和六个不同领域上进行了评估。这些评估可以帮助研究人员初始化智能体,并指导微调步骤的数据收集。
- 监督微调和强化学习微调的影响:研究证明通过结构化推理,监督微调和强化学习微调的方法能够显著提高智能体在各种领域任务中的表现。
盘古智能体的框架结构
盘古智能体框架的核心是一系列内在函数 µ(・),这些函数作用于并转换智能体的内部记忆。这些内在函数对于塑造智能体的内部状态至关重要,能够影响其决策过程。与之不同的是,外部函数的目的是直接与环境交互,触发智能体的动作。
框架支持多种复合方法的创建,结合了树搜索算法(如广度优先/深度优先搜索和蒙特卡洛树搜索),以提高语言模型的决策能力和规划能力。
盘古智能体的应用范围与评估
盘古智能体框架适用于多个任务领域,例如 ALFWorld、GSM8K、HotpotQA 和 WebShop。其交互界面类似于 OpenAI Gym,具有较高的开放性设计。
在广泛的评估中,研究者采用一系列方法对盘古智能体进行了测试,发现复合方法在提升智能体收益方面通常优于一阶嵌套方法。监督微调和强化学习微调也显示出对智能体专业化和任务收益的显著提高。
盘古智能体框架的出现为 AI 强化学习领域带来了新的可能性,其结构化推理的引入为智能体在多任务环境中的学习和适应提供了新的解决方案。这项创新的工作预示着未来 AI 强化学习领域的潜力与发展方向。