谷歌最近发布了早期测试版本的Gemini 1.5 Pro,这是一款中型多模态模型,涉及文本、视频和音频处理。它的性能与谷歌迄今为止最大的模型1.0 Ultra相似,但引入了长上下文理解的突破性实验特征。
创新功能
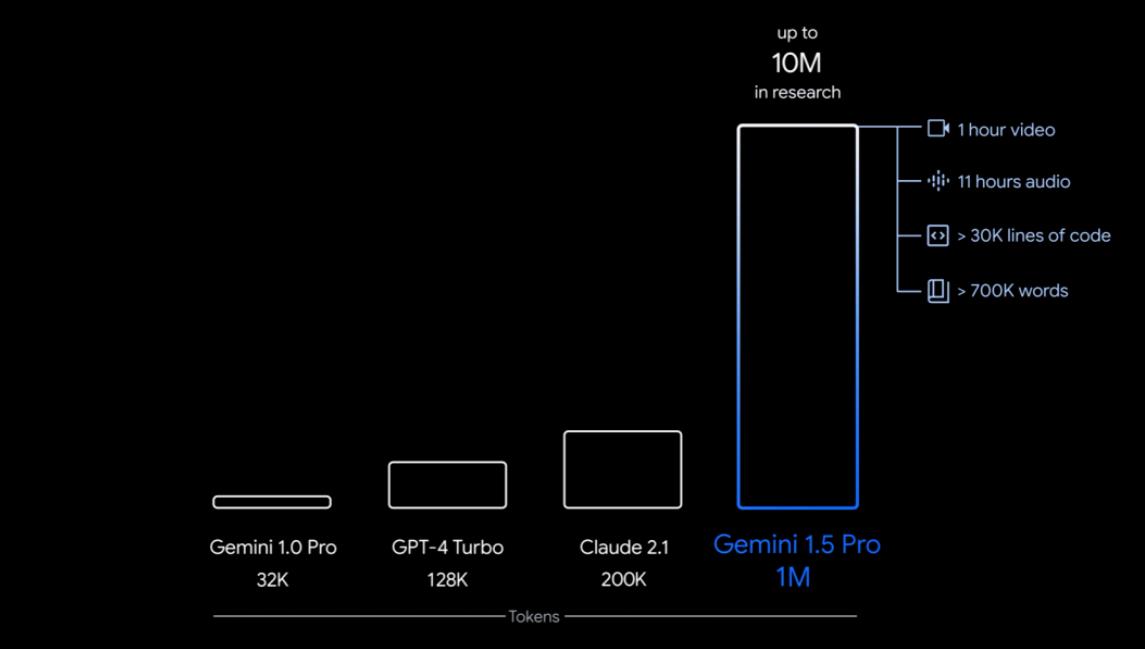
Gemini 1.5 Pro具有处理大规模内容的能力,能够稳定处理高达100万token的输入,极限情况下可达1000万token,创下了最长上下文窗口的记录。这一突破性功能使其在处理大规模数据时表现出色。
除了处理大规模数据外,Gemini 1.5 Pro还展示了在语言翻译和代码理解方面的惊人能力。仅凭一本500页的语法书、2000条双语词条和400个额外的平行句子,它就能学会一门小语种的翻译,而且翻译质量接近于人类水平。
强大表现
Gemini 1.5 Pro经过测试,表现出了超乎预期的强大功能。有用户尝试将整个代码库连同问题一起输入,Gemini 1.5 Pro不仅理解了整个代码库,还识别出了最紧急的问题并提出了解决方案。在其他代码相关测试中,它展现了强大的检索能力、理解能力和跨模态的能力,为用户提供了全面的支持。
对传统方法的挑战
Gemini 1.5 Pro展示出处理超长上下文的能力,引发了人们对传统方法的思考。一些研究者开始质疑传统的RAG方法是否仍然必要。RAG(检索增强生成)通常包括两个阶段:检索上下文相关信息和使用检索到的知识指导生成过程。然而,Gemini 1.5 Pro的能力使得传统的RAG方法显得不再那么必要。
符尧的见解
在一个测试中,一位网友表示Gemini 1.5 Pro的超长上下文处理能力实现了RAG无法做到的事情。他认为,如果一个模型能够直接处理1000万token的上下文信息,那么就不再需要额外的检索步骤来寻找相关信息。Gemini 1.5 Pro本身就是一个强大的检索器,为何还需要额外的工程来建立一个弱小的检索器呢?
综上所述,谷歌Gemini 1.5 Pro以其强大的性能和创新功能成为了AI世界的新宠。其能力不仅挑战了传统方法,还引领着人工智能技术的发展方向。