引言
学习如何使用简单的Python API将高级的AI多模态模型集成到项目中是一项令人兴奋的任务。在本教程中,我们将重点介绍Gemini API,并探讨如何在机器上进行设置,以便开始利用其强大的功能。我们还将深入研究各种Python API函数,包括文本生成和图像理解,以便为项目增加更多智能的功能。
Gemini AI模型简介
Gemini是由谷歌研究院和谷歌DeepMind等团队合作开发的新型AI模型。它是一个多模态模型,可以处理和理解多种类型的数据,包括文本、代码、音频、图像和视频。Gemini被设计为目前谷歌开发的最先进、最庞大的AI模型之一,具有灵活性和高效性,可以在各种系统上高效运行,从数据中心到移动设备。
Gemini提供了几个版本,以满足不同的用例需求:
- Gemini Ultra:最先进的版本,可以执行复杂的任务。
- Gemini Pro:性能良好且可扩展性强的版本。
- Gemini Nano:专为移动设备设计的版本。
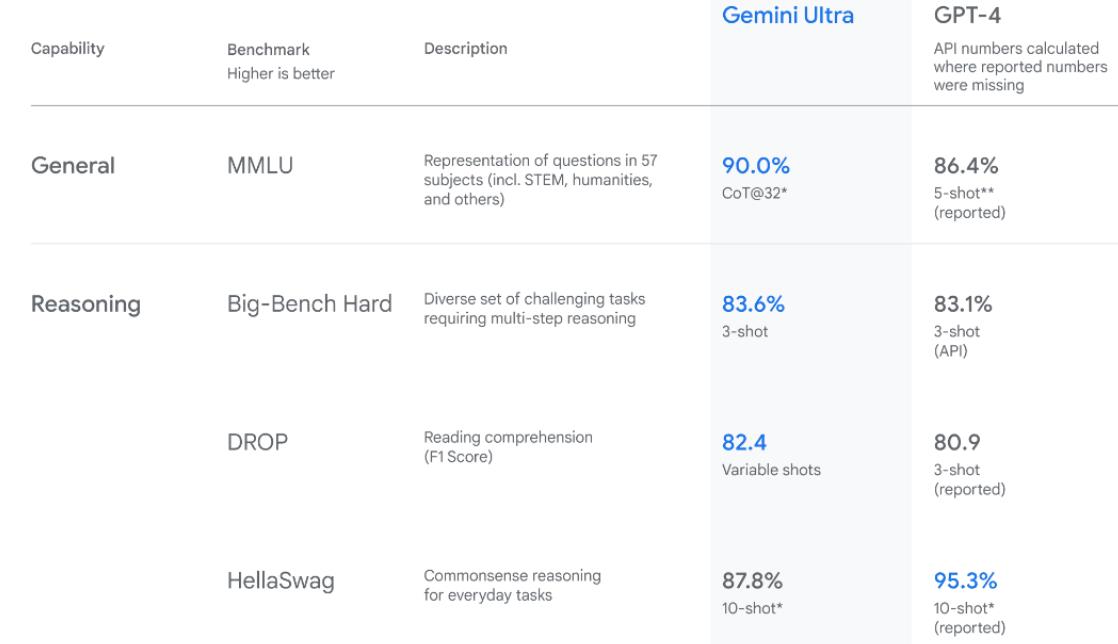
Gemini Ultra在性能上超越了以往的模型,在多任务语言理解基准测试中表现出色,展示了其先进的理解和解决问题的能力。
设置Gemini API
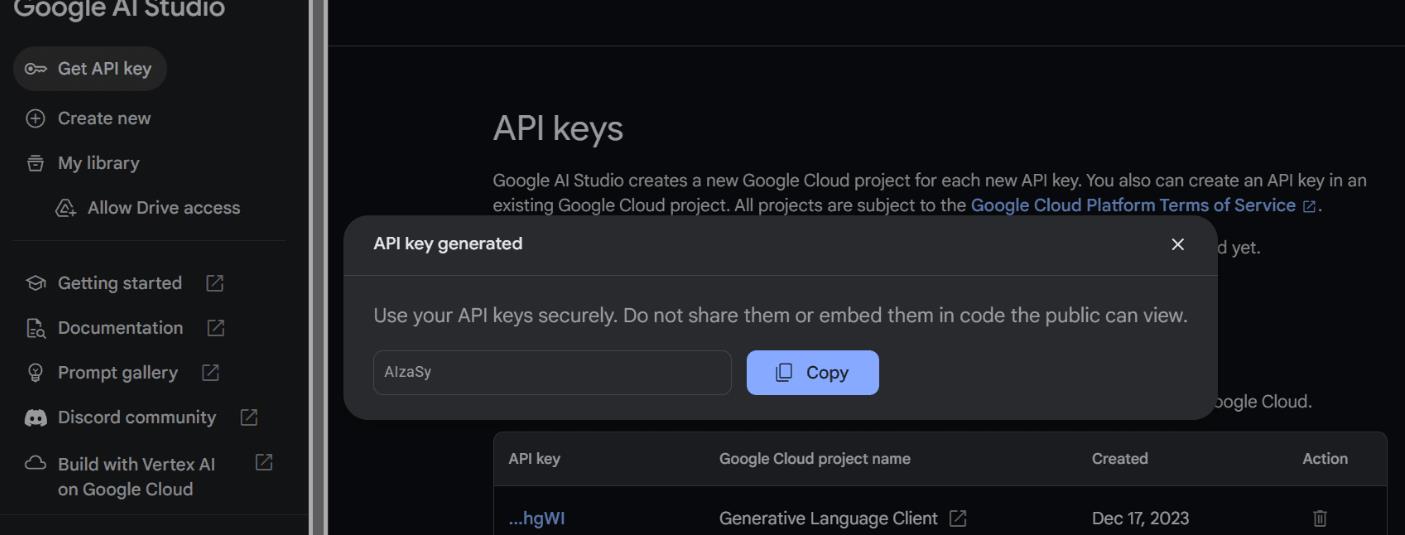
要使用Gemini API,首先需要获取一个API密钥,可以通过谷歌官方网站获取。获取API密钥后,将其设置为环境变量,以便在Python代码中进行调用。在使用PIP安装Python API后,可以根据谷歌的GenAI设置API密钥,并初始化Gemini实例,以便开始使用其功能。
import google.generativeai as genai
import os
gemini_api_key = os.environ["GEMINI_API_KEY"]
genai.configure(api_key=gemini_api_key)
使用Gemini Pro进行文本生成
设置好API密钥后,使用Gemini Pro模型生成内容非常简单。只需向generate_content函数提供一个提示,并将输出显示为Markdown格式即可。
from IPython.display import Markdown
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Who is the GOAT in the NBA?")
Markdown(response.text)
Gemini可以为一个提示生成多个响应,称为候选响应。你可以选择最合适的一个。配置响应时,可以使用generation_config变量进行定制,包括设置候选响应计数、停止词、最大token和温度等参数。
流式传输响应
除了一次性获取响应外,还可以使用stream参数来流式传输响应,以提高速度和效率。
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Write a Julia function for cleaning the data.", stream=True)
for chunk in response:
print(chunk.text)
使用Gemini Pro Vision进行图像理解
除了文本生成,Gemini还可以用于图像理解。通过加载图像并将其提供给Gemini Pro Vision模型,可以获得关于图像内容的智能理解。
import PIL.Image
# 加载图像
img = PIL.Image.open('images/photo-1.jpg')
# 显示图像
img
# 使用Gemini Pro Vision模型进行图像理解
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)
结论
通过本教程,我们学习了如何使用Gemini API将高级的AI多模态模型集成到Python项目中。从设置API密钥到使用不同版本的Gemini模型进行文本生成和图像理解,我们探索了各种功能和用例。Gemini的灵活性和高效性使其成为构建智能应用程序的强大工具,有望改变企业和开发人员的工作方式。