自从ChatGPT和类似的LLM推出以来,出现了大量的RAG工具和库。人们需要了解如何使用LlamaIndex和ChatGPT的无代码RAG。
RAG工具的重要性
检索增强生成(RAG)是利用大型语言模型(LLM)的关键工具之一。它使LLM能够将外部文档合并到其响应中,从而更好地满足用户需求。尤其在需要考虑事实准确性的情况下,这种功能非常有益。
自从ChatGPT和类似的LLM问世以来,许多RAG工具和库已经涌现出来。以下是关于RAG工作原理以及如何与ChatGPT、Claude或其他LLM一起使用的重要信息。
RAG的优势
当开发人员与大型语言模型进行交互时,模型会利用其训练数据中嵌入的知识来生成响应。然而,由于训练数据的规模超出了模型的参数范围,导致生成的响应可能不够准确。此外,训练数据中的信息可能会导致模型混淆细节,产生所谓的“幻觉”。
在某些情况下,开发人员可能希望模型能够利用未包含在训练数据中的信息,如最新发布的新闻、学术论文或公司文档。这就是RAG的价值所在。
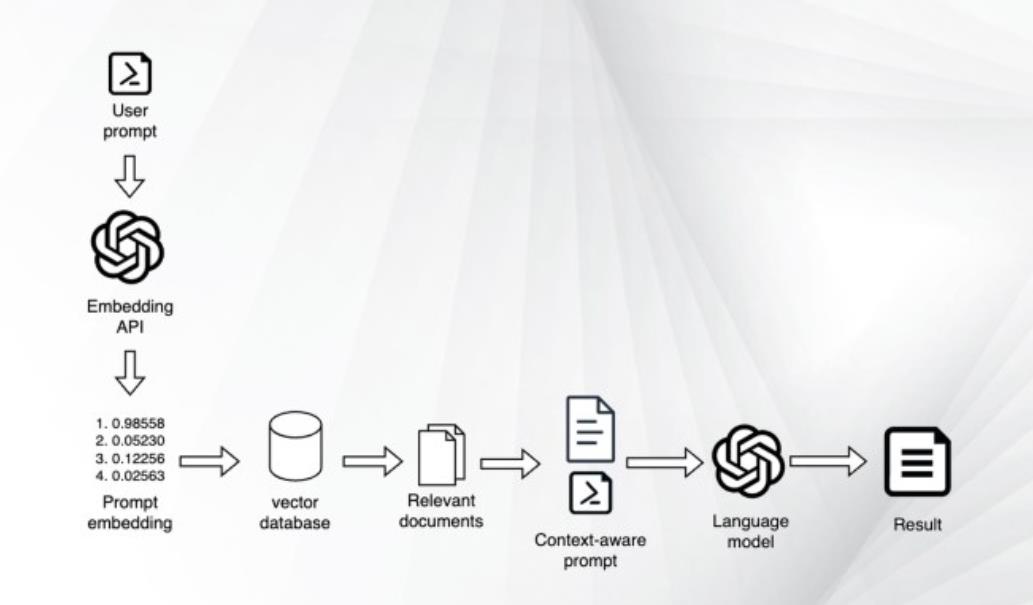
RAG通过在模型生成响应之前为其提供相关信息来解决这些问题。它会从外部源检索文档,并将其内容插入到对话中,以提供上下文给模型。
这一过程提高了模型的准确性,并使其能够基于提供的内容生成响应。实验表明,RAG能够显著减少“幻觉”。在需要最新或特定于客户的信息的应用程序中,它也被证明是非常有用的。
简而言之,标准的LLM和支持RAG的LLM之间的区别就好像是两个人回答问题。标准的LLM就像一个只能根据记忆回答问题的人,而支持RAG的LLM则像是另一个人,可以根据阅读文件的内容来回答问题。
RAG的工作原理
RAG的工作原理相对简单。它会确定与查询相关的一个或多个文档,将它们合并到提示中,并修改提示以包含模型基于这些文档的响应的说明。
开发人员可以手动实现RAG,方法是将文档内容复制粘贴到提示中,并指示模型基于该文档生成响应。
然而,RAG管道将这一过程自动化以提高效率。它首先将用户的提示与文档数据库进行比较,检索与主题最相关的文档。然后,RAG管道将这些文档的内容集成到提示中,并添加指令以确保模型生成的响应与文档的内容一致。
RAG管道需要什么?
虽然RAG是一个直观的概念,但其执行需要多个组件的无缝集成。
首先,需要一个主要的语言模型来生成响应。除此之外,还需要一个嵌入模型将文档和用户提示编码为数字列表或“嵌入”,表示其语义内容。
其次,需要一个矢量数据库来存储这些文档嵌入,并在每次收到用户查询时检索最相关的文档嵌入。在某些情况下,排序模型还可以帮助进一步细化文档的顺序。
对于某些应用程序,开发人员可能希望将用户提示分为几个部分,每个部分都需要自己的嵌入和文档,以提高生成响应的准确性和相关性。
如何在无代码环境中开始使用RAG?
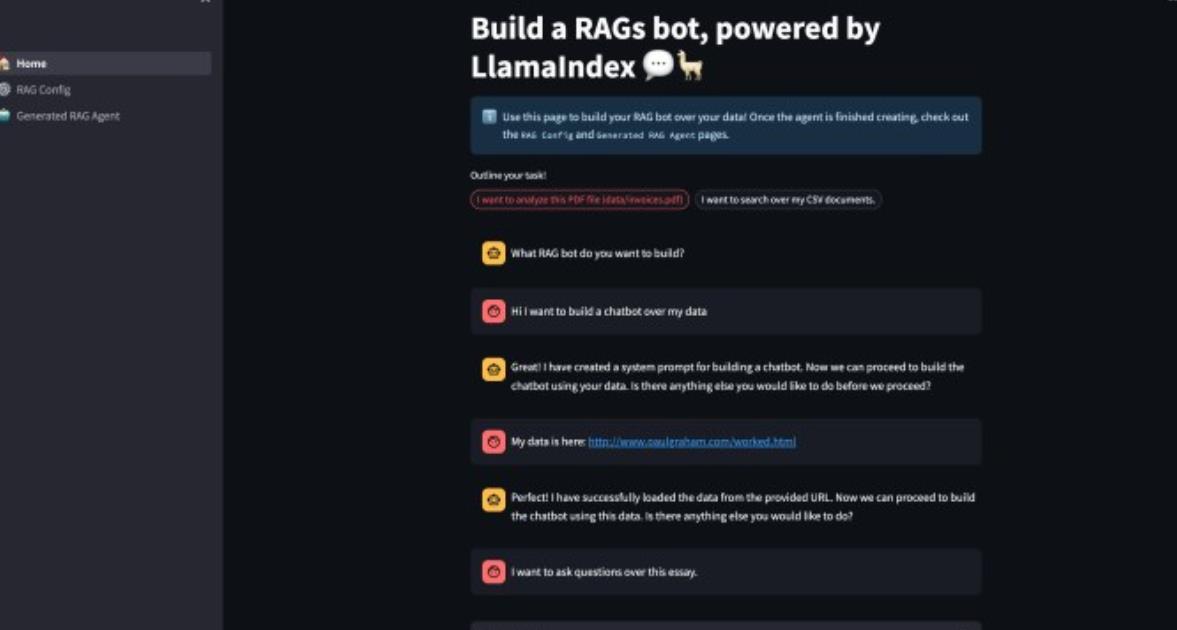
最近,LlamaIndex发布了一个开源工具,允许开发人员开发基于RAG的应用程序,几乎不需要编写代码。虽然目前仅限于单个文件,但未来可能会增加对多个文件和矢量数据库的支持。
该项目建立在Streamlit web应用程序框架和LlamaIndex之上,后者是一个强大的Python库,特别适用于RAG。
安装该工具相对简单:只需克隆存储库,运行安装命令,然后按照说明添加OpenAI API令牌即可。
尽管目前配置为与OpenAI模型一起工作,但可以修改代码以支持其他模型,例如Anthropic Claude、Cohere模型或服务器上托管的开源模型。
应用程序的初始运行需要设置RAG代理,确定文件、分块大小和检索块的数量等设置。在此之后,应用程序将为RAG代理创建一个配置文件,并用它来运行代码。
总的来说,RAG是一个有价值的工具,可以从增强检索开始,并在此基础上进行扩展。有关详细信息,可以参考相关网站上的完整指南。