DeepSeek MoE(深度求索混合专家模型)最新推出的版本引起了广泛关注。这个模型的参数量达到了160亿,但实际激活参数量只有28亿左右。与其自家的7B密集模型相比,这两者在19个数据集上表现各有卓越之处,但整体上相差不远。
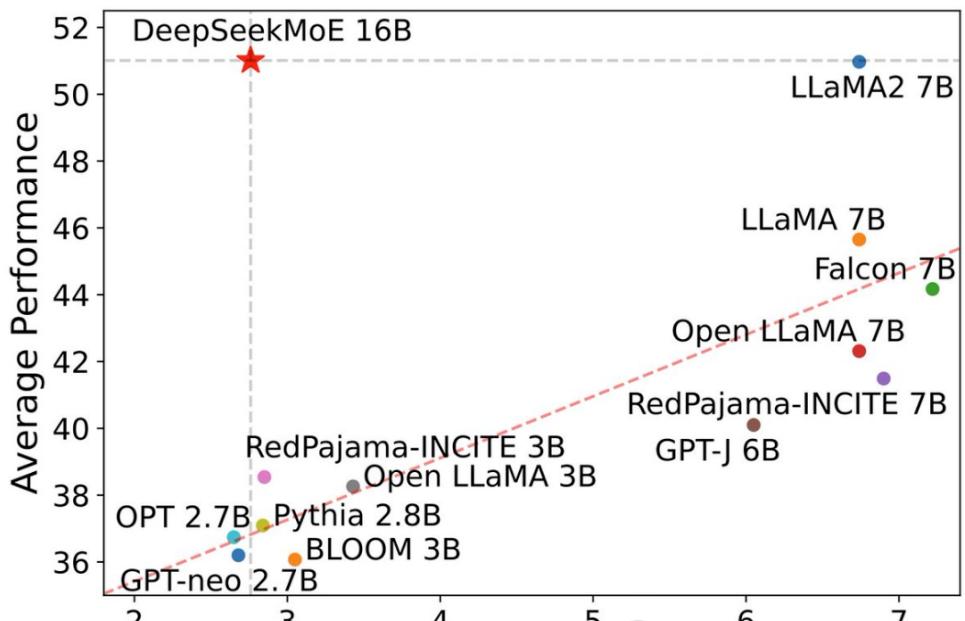
性能对比
DeepSeek MoE在性能上不逊于密集的Llama 2-7B模型,但计算量却只有后者的40%。这使得DeepSeek MoE成为一种高效的解决方案,特别是在数学和代码能力方面对Llama形成了碾压。
在一项计算量减少60%的测试中,DeepSeek MoE在20亿参数量时的性能表现尤为引人注目。与同为MoE模型的GShard 2.8B相比,DeepSeek MoE以更少的计算量实现了相当甚至更好的效果。这种高效性在机器学习领域中具有巨大的吸引力。
社区反响
DeepSeek团队发布后的第一天就在社交媒体上引起了大量关注。专业人士对其进行了测试,并在推文中表示,DeepSeek MoE的chat版本在性能上略胜于微软的“小模型”Phi-2。此外,该模型在GitHub上获得了300+星标,并登上了Hugging Face文本生成类模型排行榜的首页。
JP摩根的机器学习工程师Maxime Labonne在测试后对DeepSeek MoE表示赞赏,这也为该模型的表现提供了额外的认可。
节约计算量的关键
DeepSeek MoE的主打特色之一就是节约计算量。在一张表现-激活参数量图中,该模型在整个图表中占据了左上角的大片空白区,凸显了其在性能和计算效率方面的优势。
此外,深度求索团队还基于SFT微调对DeepSeek MoE的Chat版本进行了测试,结果显示其性能接近自家密集版本和Llama 2-7B。这表明DeepSeek MoE在不同场景下都能够表现出色。
未来展望
深度求索团队透露,他们正在研发DeepSeek MoE的145B版本。初步试验显示,这一版本对GShard 137B具有领先优势,并以28.5%的计算量达到与密集版DeepSeek 67B模型相当的性能水平。一旦研发完成,团队将对145B版本进行开源,为机器学习领域注入新的活力。
总体而言,DeepSeek MoE的出现标志着中国在开源机器学习领域取得了重要的一步。其高效的性能和计算效率使其成为研究和应用领域的有力工具,也为未来的技术发展提供了崭新的可能性。