谷歌最新推出的Gemini,一直以来都在与GPT系列进行着激烈的竞争。Gemini Pro作为重磅复仇神器,却在常识推理任务中被发现落后于OpenAI的GPT模型。然而,最近一篇由斯坦福和Meta的学者发表的论文为Gemini正名,揭示了Gemini的真正潜力。
Gemini的推理能力究竟如何?
在以往的评估中,Gemini Pro似乎在常识推理方面与GPT-3.5 Turbo存在一些差距。CMU的论文和实验显示,Gemini Pro在多方面能力上稍显不足。然而,最新的研究表明,之前的评估或许并未全面反映Gemini的潜力。
新的测试集中,Gemini在推理能力上取得了显著的提升。斯坦福和Meta的研究人员认为,以前的评估基于有限数据集(HellaSWAG),未能完全捕捉到Gemini在常识推理方面的真正实力。
斯坦福与Meta的研究
为了更全面地评估Gemini的常识推理能力,斯坦福和Meta的研究人员设计了跨模态整合常识知识的任务。他们对12个常识推理数据集进行了全面分析,涵盖了一般任务到特定领域的任务。
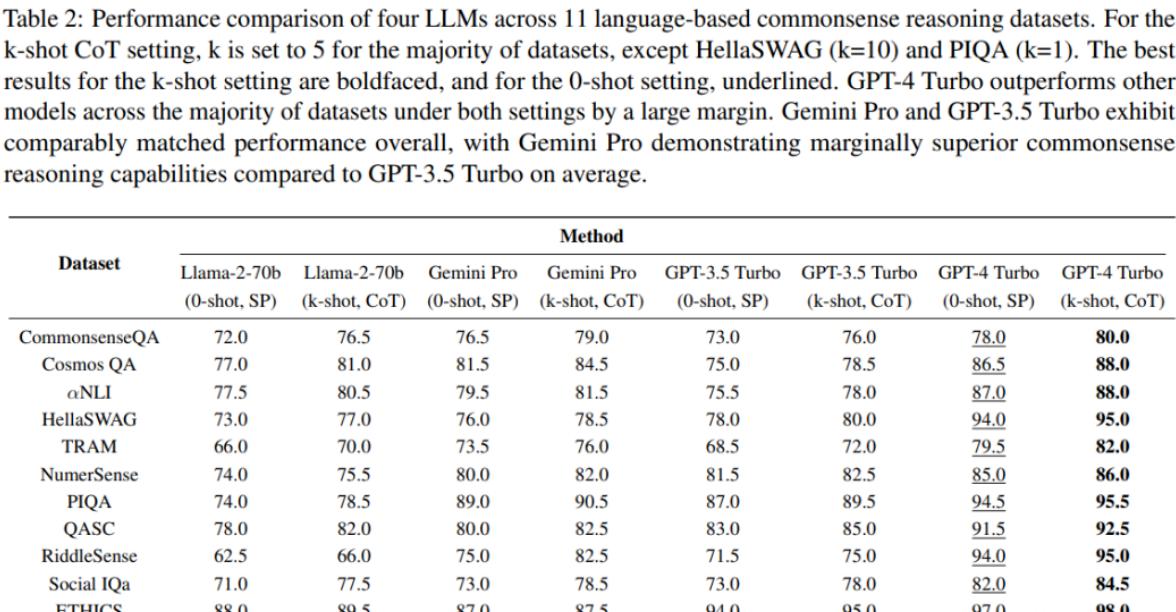
在4个LLM实验和2个MLLM实验中,研究者证明了Gemini在常识推理方面具有相当强大的能力。通过对流行的模型进行评估,他们发现Gemini Pro的性能与GPT-3.5 Pro相当,虽然在准确性上稍逊于GPT-4 Turbo。
实验细节与结果
实验数据集
研究中采用了12个与不同类型的常识推理相关的数据集,包括基于语言和多模态的数据集。这些数据集涵盖了一般推理、专业推理、社会和道德推理等不同领域。
实验模型
研究使用了四个大模型:Llama 2-70b、Gemini Pro、GPT-3.5 Turbo和GPT-4 Turbo。每个模型使用相应的API密钥进行访问。
实验方法
在评估基于语言的数据集时,研究人员采用了零样本标准提示(SP)和少样本思维链(CoT)提示。对于多模态数据集,利用零样本标准提示进行评估。
实验结果
整体性能比较显示,GPT-4 Turbo在各方面表现最为出色。在零样本学习中,它相比第二名的Gemini Pro高出7.3%,在少样本学习中更是达到9.0%的优势。
在多模态VCR数据集上的比较中,GPT-4 Turbo同样领先。Gemini Pro与GPT-3.5 Turbo的性能相当,但在某些方面略胜一筹。
结论
综合研究结果,Gemini在常识推理任务中的表现并非一直劣于GPT-4。新的测试集设计更能准确评估Gemini的潜力,表明其在推理能力上有了显著提升。然而,各模型在不同领域和任务中仍存在一些差异,这需要更深入的研究来解析。Gemini与GPT-4的竞争仍将是人工智能领域一个备受关注的话题。