上周末,Mistral发布的磁力链接震惊了开源社区,一个7B×8E的开源MoE大模型性能达到了LLaMA2 70B的水平。根据Jim Fan的猜测,如果Mistral内部训练了34B×8E或者甚至100B+×8E级别的模型,那么他们的能力可能已经无限接近GPT-4了。
MoE简介
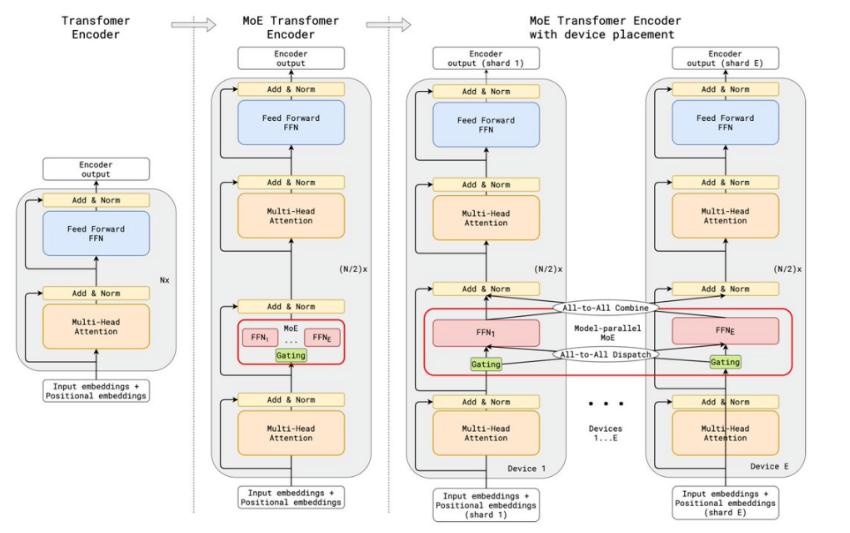
MoE(专家混合)是一种神经网络架构设计,集成了专家/模型层,特别在Transformer模块中有着广泛应用。它的核心思想是通过专家子模型动态处理输入数据,从而实现更高效的计算和更好的结果。
MoE的核心组件
- 专家(Expert): MoE层由许多专家、小型MLP或复杂的LLM组成。
- 路由器(Router): 确定将哪些输入token分配给哪些专家。有两种路由策略:token选择路由器或路由器选择token。
MoE的优势
- 每个专家可处理不同任务或数据部分。
- 可向LLM添加可学习参数,不增加推理成本。
- 利用稀疏矩阵的高效计算。
- 并行计算所有专家层,充分利用GPU的并行能力。
- 有效地扩展模型,减少训练时间,以更低的计算成本获得更好的结果。
MoE在实际应用中
对于复杂的数据集,MoE将任务分解为局部子集,并使用专家模型处理每个子集。这种团队合作技术通过将大任务分解成小任务,使得不同专家处理各自领域,最后由法官选择最佳结果。对于复杂的数据集,可以使用领域知识或无监督聚类算法将问题划分为子任务,然后为每个子集训练专家模型。
稀疏门控专家混合层
这种方法包含多个专家网络,每个专家网络都是一个前馈神经网络和一个可训练的门控网络。门控网络负责选择专家的稀疏组合来处理每个输入。这种稀疏性和专家选择是针对每个输入动态实现的,具有高度的灵活性和适应性。这种方法在算力上更高效,实现了算得快、消耗少、省钱的效果。
MoE和Transformer
MoE可以集成到Transformer的结构中,替代前馈层,实现对不同任务的高效处理。MoE层在Transformer中的作用主要体现在两个关键组件:专家模型和路由模块。这种结构使得每个专家可以专注于特定任务,同时在不增加推理成本的情况下向LLM添加可学习参数。
MoE开源再受关注
除了Mistral的开源MoE模型外,谷歌和英伟达也在这一领域做出了贡献。英伟达实习生Fuzhao Xue团队在4个月前开源了一个80亿参数的MoE模型(项目地址),采用了大量的编程相关数据来提升模型的推理能力。
面临的挑战和机遇
MoE基础设施建设
MoE拥有大量可训练参数,理想的软件环境应支持不同级别的并行,同时支持激活卸载和权重量化,以减轻内存占用。
MoE指令微调
指令微调是与MoE模型协调一致的有效方式,展示了基于MoE的语言模型潜在的巨大潜力。
MoE评估
MoE模型的归纳偏置可能在困惑度之外产生其他效果,这是未来研究的方向。
硬件挑战
GPU在跨节点通信方面面临挑战,但NVIDIA的DGX GH200解决了通信带宽问题,为开源领域的MoE模型提供了帮助。
总体而言,MoE作为构建高效大模型的关键技术,正面临着挑战,但也为语言模型领域带来了新的机遇。