最近,一位名为Devin的AI软件工程师正式亮相,他以其独特的能力引爆了整个技术界。Devin不仅可以轻松解决编码任务,还能自主完成软件开发的整个周期,从项目规划到部署,包括构建网站、修复BUG、训练和微调AI模型等。他的强大能力让众多码农感到绝望,纷纷担心程序员的末日即将来临。
在众多测试中,Devin在SWE-Bench基准测试中的表现尤为引人注目。SWE-Bench是一个评估AI软件工程能力的测试,重点考察大模型解决实际GitHub问题的能力。Devin以独立解决13.86%的问题率高居榜首,远远超过了GPT-4仅有的1.74%得分,让其他AI大模型望尘莫及。这一强大的性能引发了人们对未来软件开发中AI角色的思考。
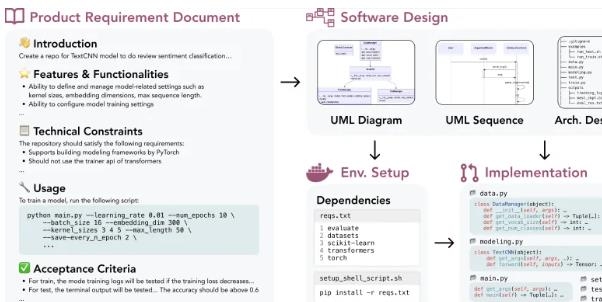
为了更全面地评估大模型的能力,上海人工智能实验室联合字节跳动SE Lab的研究人员以及SWE-Bench团队提出了一个新的测试基准——DevBench。这个基准测试从产品需求文档(PRD)到完整项目开发的各个阶段进行评测,包括软件设计、依赖环境搭建、代码库级别代码生成、集成测试和单元测试等。实验证明,DevBench可以揭示大语言模型在软件开发不同阶段的能力短板,如面向对象编程能力不足、无法编写复杂的构建脚本以及函数调用参数不匹配等问题。虽然大语言模型在独立完成中小规模软件项目开发方面还有一段路要走,但DevBench为模型的改进提供了宝贵的洞见。
DevBench的数据集包含4种编程语言、多个领域,共22个代码库,对语言模型设置了巨大的挑战。这个基准测试不仅揭示了现有大语言模型在软件开发中的局限性,也为未来模型的改进提供了指导。同时,DevBench的开放性和可扩展性意味着它可以适应不同的编程语言和开发场景,并且欢迎社区的参与共建。
除了DevBench,还有OpenCompass大模型评测体系,它是上海人工智能实验室开发的一站式评测平台,面向各类模型进行评测。OpenCompass具有可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式以及灵活化拓展等特点。DevBench作为OpenCompass的一部分,拓宽了其在智能体领域的评测能力。
Devin在SWE-Bench的卓越表现引发了对他在其他评测场景中能否延续优异表现的猜测。随着AI软件开发能力的持续发展,人们对码农和AI的较量充满期待。AI在软件工程领域的进一步发展将极大推动技术的创新和应用。