生成式AI作为一种人工智能技术,引起了广泛的关注。生成式AI可以生成各种类型的内容,包括文本、图像、音频和合成数据。那么,什么是人工智能?人工智能与机器学习有何区别?
作为一门学科,人工智能研究的是能够推理、学习和自主行动的智能代理的创建。它与构建能够像人类一样思考和行动的机器的理论和方法有关。在人工智能这个学科中,机器学习是一个重要的领域。机器学习是通过训练模型来根据输入数据进行预测的程序或系统。训练过的模型可以从新的或未见过的数据中进行有用的预测,从而应用于各种领域。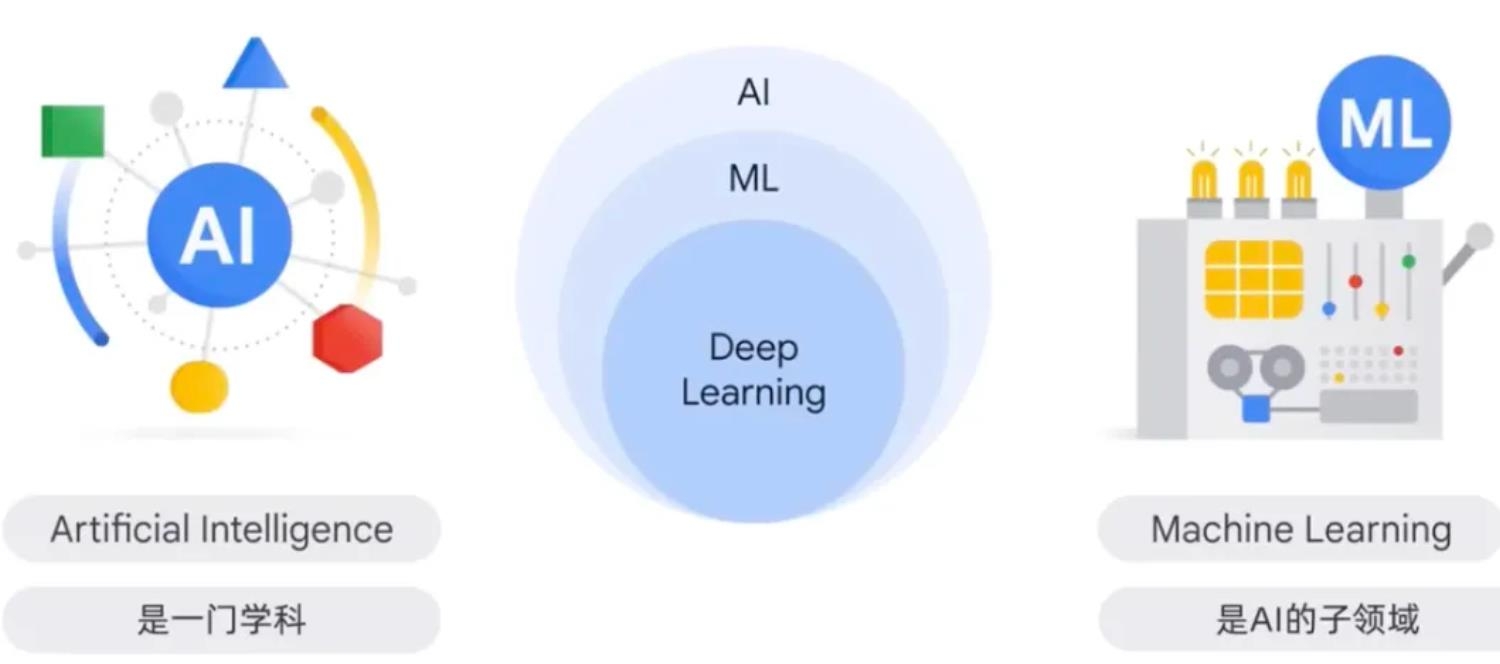
机器学习赋予计算机学习的能力,无需显式编程。常见的机器学习模型有监督学习和无监督学习。监督学习使用带有标签的数据进行训练,标签是指数据的名称、类型或数字等。通过学习过去的数据,模型可以预测未来的值。而无监督学习则是使用未标记的数据,通过观察数据的分布、聚类等方式来发现数据的内在结构。
以餐馆老板为例,如果根据过去订单的类型、小费金额以及是取货还是送货来训练模型,那么这个模型就可以根据订单类型和总金额来预测未来的消费金额。这就是监督学习模型的应用。
而无监督学习模型则可以通过观察员工的任期和收入等信息,将员工进行分组或聚类,以发现是否有人在快速通道上。无监督学习模型的应用是通过观察数据的分布情况来进行无标签的数据分析。
这些概念是理解生成式AI的基础。通过监督学习和无监督学习,我们可以训练模型进行预测和数据分析。而深度学习则是机器学习的一种方法,它使用人工神经网络来处理比传统机器学习更复杂的模式。
人工神经网络受人脑的启发,它由许多相互连接的节点或神经元组成,通过处理数据和做出预测来学习执行任务。深度学习模型通常有多层神经元,使其能够学习更复杂的模式。而且,神经网络可以使用标记和未标记的数据进行训练,这就是半监督学习的概念。半监督学习利用少量标记数据和大量未标记数据进行训练,标记数据有助于学习任务的基本概念,而未标记数据有助于泛化到新的例子。
在人工智能学科中,使用人工神经网络可以处理标记和未标记数据,实现监督、非监督和半监督学习。同时,大型语言模型也是深度学习的一个子集,可以生成各种类型的内容。
深度学习可以分为判别式和生成式两种。判别模型用于分类或预测数据点的标签,它们通常在标记数据集上进行训练,并学习数据点的特征和标签之间的关系。而生成模型则是根据现有数据的概率分布生成新的数据实例,从而产生新的内容。
判别模型可以区分不同类型的数据实例,而生成模型可以生成新的数据实例。通过传统的机器学习模型和生成式AI模型的对比,可以清晰地看到数据与标签之间的关系,以及生成模型可以生成新内容的能力。